Figure 1. Thread methods compared
[ Fabrizio Oddone | Italian Recipes | Ricette Italiane | Y2K | Site Map | What's New ]
The source code is also available separately.
Thanks to Matt Neuburg, former Managing Editor at MacTech, for having proposed me to write an article about the Thread Manager, and to Steve Sisak whose suggestions helped clarifying some issues and especially the charts.
Here is some feedback on the article, containing additional insight.
Update: At long last the Multiprocessing (MP) API Library can run on systems with Virtual Memory enabled! This is fixed in Mac OS 8.6, as documented in TechNote 1163: Mac OS 8.6 - Multiprocessing API Library.
Update: If you need threads that are compatible all the way back to System 7, you should check out Red Shed Threads. The Red Shed website also has the best papers about concurrent processing on the Mac I've ever seen, including details on how atomic instructions work on the 68K and the PowerPC.
Purpose of this article is to invite developers not to overlook the current Thread Manager preemptive capabilities, and to use them to improve application responsiveness on 680x0 Macs; this may even prove useful in preparation for Mac OS 8. In the process I point out some shortcomings and suggest workarounds.
Preemptive threads did not preempt after the first threaded application launched in Threads 2.0.1. This was fixed.Apple, in their infinite wisdom, does not tell us how to detect the fundamental bug fix (did I miss a TechNote?); the Universal Headers 2.1.2 (the ones included with CodeWarrior 10) lack the relevant information as well. We lucky Gestalt Selectors List dwellers (thanks to Rene G.A. Ros for maintaining the mailing list, by the way) have figured out a tentative answer:
Listing 1: Gestalt.c
GestaltCheck
Checks whether a reliable Thread Manager is installed. This routine should deliver TRUE if you can safely call the Thread Manager API, FALSE otherwise.
Boolean GestaltCheck(void)
{
enum {
// preemptive scheduler fix present?
gestaltSchedulerFix = 3
};
long Gresp;
Boolean pThreads = false;
if (TrapAvailable(_Gestalt)) {
if (Gestalt(gestaltThreadMgrAttr, &Gresp) == noErr) {
pThreads = (Gresp & (1L << gestaltThreadMgrPresent)) &&
(Gresp & (1L << gestaltSchedulerFix));
}
}
// If we are compiling for the Code Fragment Manager,
// check whether we can successfully call the library.
// Remember that ThreadsLib should be imported "weak".
// The gestaltThreadsLibraryPresent bit is not correctly set
// sometimes, so we don't rely on it.
#if GENERATINGCFM
if (pThreads)
if (NewThread == (void *)kUnresolvedCFragSymbolAddress)
pThreads = false;
#endif
return pThreads;
}
Since preemptive threads do not work as expected under outdated Thread Managers and a fixed
version is freely available, your best bet is requiring the bug fix at all times. This is not official Apple
gospel, so you will have to take my word for it.
In the past years Copland's name has been bandied about often enough; I shall now turn to what is available today.
Preemptive threads are not required to make yield calls to cause a context switch (although they certainly may) and share 50% of their CPU time with the currently executing cooperative thread. However, calling yield from a preemptive thread is desirable if that thread is not currently busy.This paragraph has given birth to an ill-conceived superstition: that any calculation would run at half the speed if assigned to a preemptive thread, all else being inactive. Thorough tests clearly demonstrate that the facts are different and somewhat surprising. I grabbed the Apple sample code implementing the Dhrystone benchmark, and I modified it in order to use either preemptive or cooperative threads (CW10 Gold Reference:MacOS System Extensions:Thread Manager:Sample Applications:68k Examples:Traffic Threads).
Our main event loop is structured like this:
Listing 2: EventLoop.c
EventLoop
This is our simple event loop. If you are calculating and need to use the CPU as much as possible, pass a zero sleep time. If the Mac is executing only your calculations and you pass X ticks, those X ticks are actually lost. Remember to reset the sleep parameter to a reasonable value (usually CaretTime if a blinking cursor is visible) when your application is idle again.
void EventLoop(void)
{
EventRecord event;
do {
if (WaitNextEvent(everyEvent, &event, 0UL, nil)) {
DoEvent(&event);
// this is a "busy" cooperative loop,
// waiting for the preemptive thread to finish;
// useful to evaluate whether the CPU is
// evenly scheduled between the main cooperative
// thread and the preemptive thread
#if _TESTBALANCE
while (gDhrystoneDone == false) ;
#endif
}
else {
// the else clause executes when no events are pending;
// since we want to give preference to the calculating thread,
// we explicitly tell the scheduler;
// if you are using many calculating threads
// keep them in a list, in order to yield to each
(void) YieldToThread(gDhrystoneThreadID);
if (gDhrystoneDone) {
// stuff used to update the window and the log file removed
gDhrystoneDone = false;
(void) SetThreadState(gDhrystoneThreadID, kReadyThreadState, kNoThreadID);
}
}
}
while ( gQuit == false );
}
We want to evaluate how much time the Mac actively spends calculating, thus we need to establish a proper frame of reference. Since we are probing the Operating System's behavior, but we want our findings independent of the relative speed of each Mac model, we set each Mac maximum performance level equal to 100%. With "maximum performance level" we mean the one obtained executing the test calculation within a cooperative thread that never yields the CPU. Note that we nitpickers are also very interested in evaluating possible behavioral changes when the application is kept in the background (as opposed to the foreground) and nothing else is running. Cooperative threads, when yielding, yield the CPU every 20 ticks (1/3 of a second); preemptive threads do not need to yield and in fact never yield in our test.
Listing 3: Yield.c
Dhrystone
This shows my calculation routine that may be called by a cooperative or preemptive thread. The symbol _COOPYIELD must be set to 0 in the latter case.
void
Dhrystone(void)
{
// other variables removed for clarity
register UInt32 Run_Index;
// the following gets compiled only when
// we don't use preemptive threads;
// this is very important since you shall NEVER
// call TickCount() within a preemptive thread!
#if _COOPYIELD
UInt32 base_Time = TickCount();
UInt32 curr_Time;
#endif
/* Initializations */
// initialization stuff removed
for (Run_Index = 1; Run_Index <= kNumber_Of_Runs; ++Run_Index) {
// if((Run_Index & 0xFFF) == 0) YieldToAnyThread();
// the above method was originally used in the Apple sample;
// decidedly unwise, since slower Macs will yield too little
// (impairing responsiveness) and faster Macs will yield too
// much (wasting precious CPU time)
// calculating stuff removed
// actual yielding code
#if _COOPYIELD
curr_Time = TickCount();
if (curr_Time > base_Time + 20UL) {
YieldToAnyThread();
base_Time = curr_Time;
}
#endif
} // loop "for Run_Index"
}
All Macs were tested when running under System 7.5.1 with extensions turned off (the System incorporates Thread Manager 2.1.1), except for the SE/30 under 32 bit mode, having MODE32 7.5 installed. If not specified, 32 bit mode is implied in any case. No other applications were running, and the mouse was left quiet.
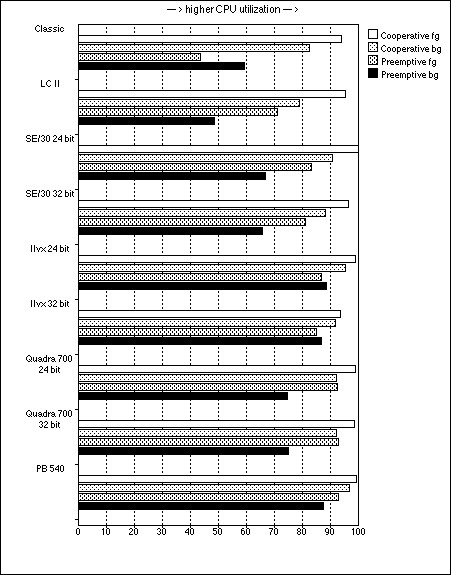
| Results | Cooperative fg | Cooperative bg | Preemptive fg | Preemptive bg |
| Classic | 93.804 | 82.401 | 43.399 | 59.169 |
| LC II | 95.413 | 78.853 | 71.072 | 48.539 |
| SE/30 24 bit | 99.994 | 90.792 | 83.112 | 66.813 |
| SE/30 32 bit | 96.599 | 88.260 | 80.976 | 65.764 |
| IIvx 24 bit | 98.913 | 95.509 | 86.642 | 88.582 |
| IIvx 32 bit | 93.640 | 91.711 | 84.880 | 86.737 |
| Quadra 700 24 bit | 98.841 | 92.274 | 92.600 | 74.585 |
| Quadra 700 32 bit | 98.593 | 92.189 | 92.994 | 74.897 |
| PB 540 | 99.354 | 96.901 | 92.743 | 87.395 |
Note that the displayed results are averaged on a reasonable number of runs (ten runs at most, sometimes less since the timings settle quickly). I always treated the first run as an outlier and discarded it (because of window updates, major context switches, etc.).
Except for a couple of Mac models, the situation is much better than one would expect, in the light of the 50% passage I have previously quoted from the Thread Manager documentation. This probably happens because of the explicit YieldToThread() call at idle time. However, our desire is to observe a constant pattern across Mac models, since we normalized our data against the faster result on each Mac. On the contrary, we cannot but spot a significant and annoying variability in the measured behavior. A chart sharply supports our contention:
Figure 1. Thread methods compared
I am completely at a loss here. The very same program under the very same Operating System version behaves differently, depending on the Mac model. Just when you thought that computers were deterministic devices... Let's now look at the same data under another perspective:

Figure 2. Macs compared
A quick glance at the chart may fool the reader into thinking that Macs perform better under 24 bit mode. This is not true, and remember the normalization trick. The absolute timings show that, in the faster calculation, 32 bit mode always outperforms 24 bit mode. To understand this, we quote develop #9 (Winter 1992), p. 87: "Turning on 32-bit addressing helps because it reduces interrupt handler overhead." Also, some parts of the Toolbox may run faster when 32 bit mode is on; notably QuickDraw. Rather unusually, when using threads the opposite happens: calculations proceed at a better pace under 24 bit mode. Apple is not known for being quick at repartee; nonetheless we are all ears, waiting for a detailed explanation upon this subject.
Even the worst case situation portrays a variable outcome, though less pronounced. We obtain this chart by setting the _TESTBALANCE symbol to 1. (See Listing 2.) We conclude that the CPU is not evenly divided between the main cooperative thread and the preemptive thread: the former has a little, but significant, Mac-dependent scheduling advantage.
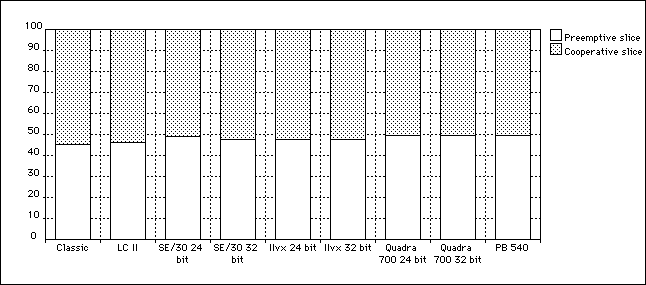
Figure 3. Worst case situation
Although with my data collection at hand I cannot but reproach the slouching gait of preemptive threads, I still think that reengineering an existing application (or writing one from scratch) letting the user choose between preemptive and cooperative threads has no contraindications of sort. The potential speed loss occurring with preemptive threads is indeed bearable, especially if you think that one popular decompression utility (hint, hint!) runs in background at an appalling speed: its CPU utilization barely reaches 2% (yes, two percent!) yet nobody looks concerned. Preemptive threads, besides increasing responsiveness, add one benefit: when your application is in front, they run even while the user is dragging things around or attempting menu selections.
One last remark for those who are screaming since the start of this section: "If you don't like the default scheduler, write your own! The Thread Manager allows this!". My answer is simple: custom schedulers are intended (at least they should be) for unusual situations, not for fairly standard programming constructs. Remember than programmers, though superhuman to some extent, are mere mortals themselves. Therefore, Donald Norman's motto is still valid: "Activities that are easy to do tend to get done; those that are difficult tend not to get done."
Listing 4: YieldRealWorld.c
DhrystoneR
This shows a real-world calculation routine used either cooperatively or preemptively, depending on a global setting.
void
DhrystoneR(void)
{
// other variables removed for clarity
register UInt32 Run_Index;
UInt32 base_Time;
UInt32 curr_Time;
/* Initializations */
if (gUseCooperative)
base_Time = TickCount();
// other initialization stuff removed
for (Run_Index = 1; Run_Index <= kNumber_Of_Runs; ++Run_Index) {
// calculating stuff removed
// actual yielding code
if (gUseCooperative) {
curr_Time = TickCount();
if (curr_Time > base_Time + 20UL) {
YieldToAnyThread();
base_Time = curr_Time;
}
}
} // loop "for Run_Index"
}
Of course the application would check at initialization time whether preemptive threads are available or not (calling NewThread() and checking for paramErr), and gray out the relevant choice in the latter case. Speaking about user friendliness, I think that most users are neither aware, nor interested in the cooperative vs. preemptive issue, so we should label the two choices avoiding technical jargon.
As a last remark, while it is true that you cannot spawn preemptive threads in native mode, you can in emulation mode. My Disk Charmer application takes advantage of it.
This is taken from Silberschatz-Galvin [1994], p. 186:
Although semaphores provide a convenient and effective mechanism for process synchronization, their incorrect use can still result in timing errors that are difficult to detect, since these errors happen only if some particular execution sequences take place, and these sequences do not always occur.See also this brief excerpt from the Ada95 Rationale:
[...] avoided the methodological difficulties encountered by the use of low level primitives such as semaphores and signals. As is well known, such low-level primitives suffer from similar problems as gotos; it is obvious what they do and they are trivial to implement but in practice easy to misuse and can lead to programs which are difficult to maintain. [...]For these reasons, the adoption of higher level constructs is advocated (interested readers may refer to the texts above cited). The semaphore/goto simile reminds me that, oddly enough, the man who first attacked gotos [Dijkstra, 1968] is the one who earlier introduced semaphores [Dijkstra, 1965].
Semaphores may be efficient, though it depends on the implementation. Months ago I had to write the customary "dining philosophers" program using the UN*X semaphore primitives. Running under HP-UX 9 on a 68040 HP workstation produced disconcerting results. You run the program (for the record, I used an asymmetric solution) with some forty semaphores/processes, and as the CPU load skyrockets, the whole computer unbelievably slows down, crawls, and withers. The hapless user at the console can barely move the mouse (if the dreaded X Window System is running), worse than some Mac models while initializing a floppy. Responsiveness improves slightly, but not to a reasonable degree, if you set the friendliest priority with the 'nice' command. By the way, did you know that UN*X has two different 'nice' commands, one built into the cshell, one available as an external command, each one having its own command syntax?
So, my advice when it comes to synchronizing primitives is: if the programming language you are using supports tasking constructs (for example, Ada95) go for it. As an added advantage, you may easily port your tasking code on different platforms. If you are stuck with a mainstream language without tasking support (Pascal, C, C++) stay with the primitives you are offered.
On a related note, on the Internet I've seen some semaphore implementations that use the Enqueue() and Dequeue() system calls. Provided that you are only using threads and not other interrupt-level code, this method is overkill because the abovementioned system calls disable interrupts. The Thread Manager API is more desirable because the relevant critical region calls disable thread preemption only, leaving interrupts enabled [Anderson-Post, 1994].
At the last minute, I discovered that somebody indeed rolled up his sleeves and wrote a better semaphore library. His name is Stuart Cheshire and his library can be found on the Apprentice CD-ROM 4 (Apprentice:Information:Programming:Stuart's Tech Notes:Stu'sThreadUtils) or on the newer Apprentice CD-ROM 5 (Apprentice 5:Source Code:C:Snippets:Stuart's Tech Notes:Stu'sThreadUtils) and maybe on the Internet, too. I have not had the time to experiment with it, but after reading his enlightening and witty technotes I am convinced that he is way competent, so his stuff may work in the end.
What is desperately needed at this point is a single, multiprocessing-scalable, levelheaded scheduling API, that runs natively on both 680x0 and PowerPC with any version of whatever system component, allowing for maximum CPU utilization in a simple way. Am I asking for too much?
That's all, folks. You have enough material to bash Apple for the next few weeks, and enough enthusiasm to dive head over heels into preemptive threads!
Anderson, Eric & friends. "Thread Manager for Macintosh Applications". Final Draft, Revision 2.0 (January 24, 1994). [CW7 Gold Reference:MacOS System Extensions:Thread Manager 2.1:Thread Manager Documentation].
Bechtel, Brian. "System 7.5 Update 1.0". TechNote OS 07 (February 1995).
Dijkstra, E. W. "Cooperating sequential processes". Technical Report EWD-123, Technological University, Eindhoven, the Netherlands, (1965). Reprinted in [Genuys, 1968], p. 43-112.
Dijkstra, E. W. "GOTO statement considered harmful". Communications of the ACM, 11.3.147 (1968). ACM Press.
Genuys, F. (editor). Programming Languages (1968). Academic Press, London, England.
Silberschatz, Abraham and Galvin, Peter B. Operating System Concepts, Fourth Edition (1994). Addison-Wesley.
"Multiprocessor API Specification" prepared by Apple Computer and DayStar Digital, Inc. for the WorldWide Developers Conference (May 1995).
Wenzel, Karen. "Running CFM-68K Code at Interrupt Time: Is Your Code at Risk?". TechNote 1084 (November 1996, later revised).
You can download for free the Ada95 Rationale at the Ada home